
Linux Container Primitives: An Introduction to Control Groups
Part seven of the Linux Container series
December 3, 2020

Next to namespaces (which we discussed in previsous posts 4 , 5 and 6 , control groups are another major building block of today’s Linux containers. This post informs about the basics regarding this kernel primitive. The following list shows the topics of all scheduled blog posts. It will be updated with the corresponding links once new posts are being released.
- An Introduction to Linux Containers
- Linux Capabilities
- An Introduction to Namespaces
- The Mount Namespace and a Description of a Related Information Leak in Docker
- The PID and Network Namespaces
- The User Namespace
- Namespaces Kernel View and Usage in Containerization
- An Introduction to Control Groups
- The Network and Block I/O Controllers
- The Memory, CPU, Freezer and Device Controllers
- Control Groups Kernel View and Usage in Containerization
Control Groups
The goal of cgroups is to enable fine-grained control over resources consumed by processes additionally to resource monitoring. Before this Linux kernel feature was available, other mechanisms such as nice or setrlimit had to be used to replicate a subset of the features that are being offered directly by today’s kernels. However, without the ability to group processes and restore previously applied settings this was not as convenient as using control groups is today. Next to namespaces this kernel feature is one of the main primitives that are being used to build container environments. Limiting and monitoring of containers with the control groups described in this section can be applied to processes as well as containers.
By organizing control groups in a virtual filesystem called cgroupfs, taking advantage of the hierarchical structure of control groups in implementations becomes possible. Control groups are created, deleted and modified by altering the structure and files of this filesystem. Also, sub-groups are possible that allow the inheritance of cgroup attributes. This implies that limits in parent groups can also apply in child groups. It’s also possible that this affects child processes - for example a fork call can cause the newly created process to be affected by the same limits as the parent. Please note that, depending on the type of control group that’s in use, these aspects may or may not be applicable.
Consider the following use-case: On Ubuntu systemd prevents systems from being crashed by fork bombs by automatically creating a default control group for each user. This behavior results from the effect of the .slice sub-group that’s limiting the number of processes a single user may create, preventing users from spawning processes in an infinite loop. By executing systemctl status user-$UID.slice the current limit is shown.
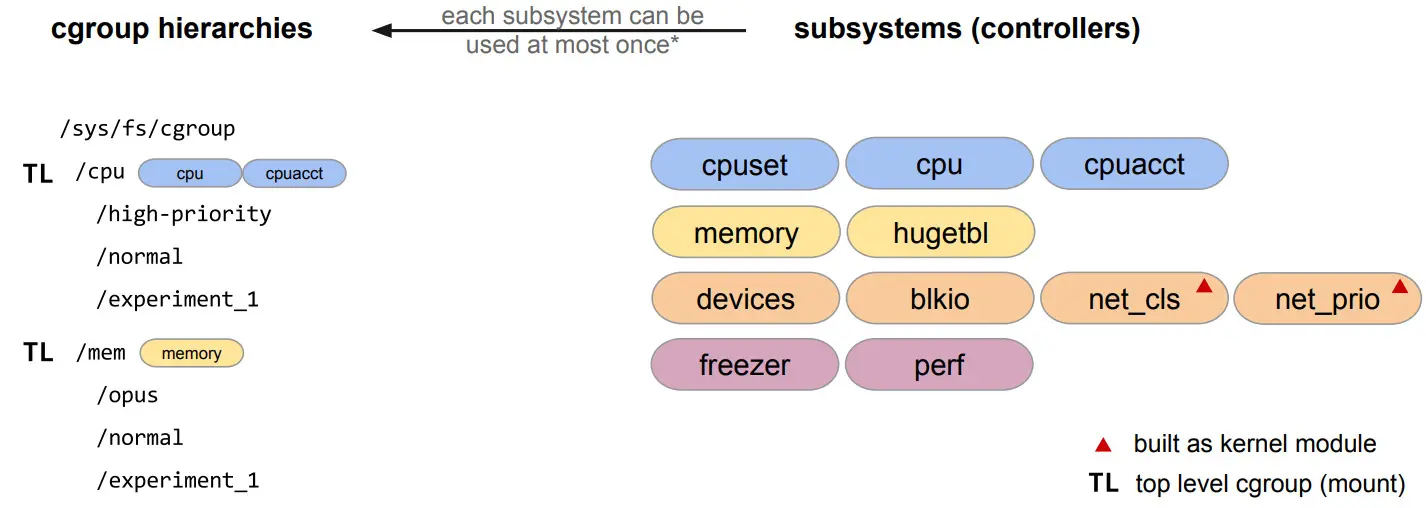
Specific parts of the offered control group configuration, like the limit described above, are configurable in a granular way using controllers. Controller types are also called subsystems of cgroups and control the aspect of resource usage that may be limited or monitored. Throughout this chapter, various controller types will be discussed. The kernel code regarding cgroups is responsible for grouping processes whereas the individual controller implementations takes care of the resource monitoring and limiting functionality itself.
Modifications to control groups can be applied once the virtual filesystem of the controller to use is mounted. One may choose to mount a single controller type or mount every available type at once. In any case, mounting controllers usually takes place in /sys/fs/cgroup where at least one folder for each controller is being created by calling mount. It’s important to note that it’s not possible to mount an already mounted controller to a different location without also mounting all other controllers that are already mounted to prevent ambiguity. The following figure illustrates the mounting procedure [1]:
Initially, all processes belong to the root control group. Creating a new cgroup is being accomplished by creating a directory for the control group under /sys/fs/cgroup/<controller type>/<cgroup name>. To configure the newly created cgroup, two tasks have to be performed:
Adding cgroup configuration by creating an attribute file with desired values. For example, to set a memory limit of 100MB for all processes in the control group
mem, the file/sys/fs/cgroup/memory/mem/memory.limit_in_byteshas to be created with content100000000[2]. For each controller, there exist multiple possible attribute files that can be used to configure a control group.Moving a process to a control group by writing the target PID to
/sys/fs/cgroup/memory/mem/cgroup.procs.
The cgroup.procs file mentioned above may be utilized by any process with write access to the respective file to move another process into a control group. However, when a PID is written to the file, an additional check is being performed to determine whether the writing user is privileged or the same user that’s the owner of the process that’s about to be moved.
Control groups can also be nested by creating sub-directories under already existing cgroup folders. It should be noted that changes made to processes and the control group configuration are not persistent. After rebooting a machine, the configuration will be lost in case cgconfig or similar mechanisms have not been used to make the changes persistent. Persistence is achieved by re-applying control group configurations upon startup. Re-mapping processes of a specific user to a control group works by using the daemon cgrulesengd in combination with a rule set. To remove a cgroup, the associated directory has to be removed which renders the control group invisible. As soon as all processes of the cgroup terminate or are considered zombies, the control group will finally be removed by the kernel.
Two cgroup versions
Due to the way control groups were originally implemented, many inconsistencies were introduced and the code was rather complex in regard to the offered features [3]. Unfortunately, the development of cgroups was not coordinated in an optimal manner which lead to the problematic first version of control groups. Since Linux 4.5, the cgroups v2 implementation is available with the intent to replace the original v1 implementation. However, as of now not all resource controllers of the original implementation are available in the newer version. Because of this, a parallel usage of both versions has to be taken into account in case specific v1 features are required. Please note that a single controller can not be used in both v1 and v2 simultaneously. Some major differences between v1 and v2 are listed in the table below:
| v1 | v2 |
|---|---|
| Multiple cgroup hierarchies possible. | Only a single, unified hierarchy is allowed. |
| Distinguishes threads and processes. Threads of a single process can be mapped into different cgroups. | No control of single threads. Therefore no tasks file. Exception: Thread mode (see below). |
| Processes can be mapped to cgroups disregarding whether a group is a leaf node of the hierarchy or not. | No internal processes rule for non-root cgroups: A group can not have controllers enabled and have child groups and processes mapped to it at the same time. |
| The release_agent can be used in order to get notified in case a group gets empty. | The events file can be used for the same purpose. |
| Implements own mount options. | Deprecates all v1 mount options. |
Uses /proc/cgroups to keep track of all controllers supported by the kernel. | Uses the cgroup.controllers file for the same purpose. |
Additionally to the cgroups file mentioned above, the following files are present to organize the control group functionality:
/sys/kernel/cgroup/delegate: Since Linux4.15it’s possible to delegate the management of a control group to an unprivileged user. This file lists all cgroup version 2 files that the delegatee should own after a delegation process./sys/kernel/cgroup/features: This file enables user-space applications to list all control group features the kernel supports./proc/<PID>/cgroup: This contains information on all cgroups a process resides in.
Thread Mode
The initial control group implementation allows distributing the threads of a process into individual control groups. At first, this seemed to provide a maximum of flexibility. However, there are cases where this resulted in problems: Threads of a single process are running in the same memory space. When limiting the available memory of one thread, this also affects all other threads that may have other memory restrictions imposed by other cgroup memberships. Undefined behavior results as multiple settings are active at the same time for the threads of a single process. Also, when moving a process into a control group after starting it, it’s often necessary to move all child threads too. A helper utility for this task is cgexec which automatically moves all threads of the created process in the correct groups.
After removing the ability to manage control groups on a per-thread basis in v2, some important use-cases could not be fulfilled anymore. This includes the ability of the cpu controller to manage threads. Because of that, Linux 4.14 added the thread mode to relax the restrictions imposed by the transition to v2.
This new mode allows to use threaded sub-trees, enabling threads of multiple processes to be mapped into different control groups within such a sub-tree. There are now two types of resource controllers:
- Domain: Controllers of this type are not thread aware, meaning that they can only work on process level. All threads of a process have to reside in the same control group. This controller type can not be enabled in threaded sub-trees.
- Threaded: This is the new controller type that allows control group management on a thread-level. It can be used in combination with threaded sub-trees.
Next post in series
- Continue reading the next article in this series The
Network
and
Block
I/O
Controllers
Follow us on Twitter , LinkedIn , Xing to stay up-to-date.
Credits
Credits: The elaboration and software project associated to this subject are results of a Master’s thesis created at SCHUTZWERK in collaboration with Aalen University by Philipp Schmied.