
Linux Container Primitives: User Namespaces
Part five of the Linux Container series
September 8, 2020

In the previous part of the Linux Container Primitive series, the PID and network namespaces were discussed. This post covers one of the most important namespace types in detail – the user namespace. The following list shows the topics of all scheduled blog posts. It will be updated with the corresponding links once new posts are being released.
- An Introduction to Linux Containers
- Linux Capabilities
- An Introduction to Namespaces
- The Mount Namespace and a Description of a Related Information Leak in Docker
- The PID and Network Namespaces
- The User Namespace
- Namespaces Kernel View and Usage in Containerization
- An Introduction to Control Groups
- The Network and Block I/O Controllers
- The Memory, CPU, Freezer and Device Controllers
- Control Groups Kernel View and Usage in Containerization
User Namespaces
This namespace type introduces mapping user and group IDs and the isolation of capabilities per-namespace. For instance, a process can run with a non-zero UID outside of a user namespace while having a UID of zero in a namespace. This ultimately enables unprivileged users to have root privileges in isolated environments. Moreover, this is the only namespace type not requiring the CAP_SYS_ADMIN capability, allowing unprivileged users to create this namespace type.
By mapping the UID in the namespace to the original UID, all changes and actions introduced by a user will be mapped to the set of privileges a user holds in the parent namespace. This prevents actions in the global system context that the user normally would not be allowed to perform. This includes sending signals to processes outside of the current namespace and accessing files [1]. For example, a user with root privileges in a namespace is not able to read the /etc/shadow file because the original privileges do not allow to do so. The same applies to the mapping of GID values. Applied changes, for example creating new files, will be shown as originating from the user outside of the namespace. Likewise, calling stat will map IDs in the opposite direction in order to create a correlation in regard to the applied mappings.
This namespace type can also be nested, similar to PID namespaces. Using ioctl operations it’s possible to inspect the relationships between different user namespaces.
By default, a process only has a specific capability in a user namespace in case it’s a member of the user namespace and the capability is present in the corresponding capability set.
Linux capabilities are aware of user namespaces as can be seen in the function has_ns_capability of kernel/capability.c: With this function the kernel is able to check whether a process, as represented by a task_struct in the kernel code, has a capability in a specific user namespace. By default, the first process in a new user namespace is granted a full set of capabilities in that namespace. While having all capabilities in the user namespace, the process does not have any capabilities in the parent user namespace. This means:
- A process with all capabilities in a user namespace is able to perform privileged operations on resources that are solely governed by this specific user namespace.
- The same process is not able to perform changes to resources governed by the parent namespace, the initial namespace or outside of namespaces. For example even with
CAP_SYS_TIMEin the user namespace it’s not possible to alter the system clock because this is not governed by a namespace type as of now and thereforeCAP_SYS_TIMEin the initial namespace is required in this example.
In case a process has the CAP_SYS_ADMIN capability it’s possible for it to enter an arbitrary already existing user namespace using setns. In that case, this process also gains a full capability set in the entered namespace. Also, if a process possesses a capability in a parent user namespace, it also has this capability in all child namespaces. All processes that run with the same UID as the process that created a user namespace have a full capability set in a namespace and all of its children. This can be verified by creating two namespaces as siblings. Processes in the parent namespace are able to use setns to switch to each of the namespaces. However, it’s not possible for one of the child namespaces to do switch to a sibling namespace because of the lack of CAP_SYS_ADMIN in the target namespace.
In the scenario of containers it’s common practice to reduce the set of available capabilities a container and all its processes may have. The reduced capability set that’s in place by default for Docker containers is present in the OCI specification’s source code [2]. Missing capabilities can be added and removed on demand when starting a new container – for simple use-cases the pre-defined set can serve as a secure base. All capabilities can be granted to a process with the privileged flag although its use should be evaluated carefully in terms of security.
Without reducing the capability set or by granting all privileges to a container, drastic changes to a system and its state may be employed in case of compromise. This includes:
- Loading custom kernel modules
- Tracing arbitrary processes to interfere with their program flow or to leak sensitive information
- Changing the ownership of arbitrary files
- Send arbitrary signals to processes
- Spoof network packets using raw sockets
As the list above suggests, reducing the capability set via user namespaces is crucial for containerization. In cases where untrusted code is being executed in containers or compromised containers are part of the threat model, changes to the host system must not be possible without explicitly allowing this kind of modification.
Every process in a user namespace has two files which can be used to perform a UID and GID mapping:
/proc/<PID>/uid_map/proc/<PID>/gid_map
By default, these files are empty. The kernel expects lines following the format
ID-inside-ns ID-outside-ns length
to be present in these files. The length parameter is used to create a range of possible IDs, starting from ID-inside-ns respectively ID-outside-ns with the maximum value according to the length field value. In case no mapping is being performed for an ID, the value of /proc/sys/kernel/overflow{u, g}id is used. This causes an ID to be mapped to the nobody ID. Also, the kernel silently prevents elevating privileges when set-user-ID binaries are being executed. Please note that an ID mapping can only be performed once and is limited to a maximum of 340 lines.
Consider the listing below which helps to understand the mapping process:
int run(void *) {
while (true) {
std::cout << "[Child] EUID/EUID "
<< geteuid()
<< "/" << geteuid()
<< std::endl;
}
return 0;
}
int main(int argc, char const *argv[]) {
[...]
childPid = clone(run, childStackTop, CLONE_NEWUSER, 0);
std::cout << "[Parent] Child PID: " << childPid << std::endl;
sleep(5);
// echo "0 1000 1" >> /proc/<PID>/uid_map
std::string cmd = "echo '0 " +
std::to_string(getuid()) +
" 1' >> /proc/" +
std::to_string(childPid) +
"/uid_map";
system(cmd.c_str());
while (true) { [...] }
[...]
return 0;
}
The code spawns a child process that prints its effective UID and GID values in an endless loop. After five seconds have passed, the parent process will perform a UID mapping in order to map the root user in the new namespace to the user executing this code. This produces the following output:
[Parent] Child PID: 22338
[Child] EUID/EUID 65534/65534
[...] // five seconds pass, mapping is done
[Child] EUID/EUID 0/0
[...]
This produces the same UID mapping as executing unshare -r /bin/bash does. With the new mapping values it’s now possible for the kernel to check the privileges a user possesses in the namespace by mapping the ID values back to the original values and performing permission checks with the values outside of the namespace. One of the use-cases for this is to allow unprivileged users on the host to be privileged in a container. After some additional configuration, this for example enables these users to configure parts of the container and install software packages. Container engines like Docker perform this task by default.
There exist certain additional rules for applying UID/GID mappings:
The UID mapping file is being owned by the user that created the namespace. Because of this, only this user and
rootare able to write to this file. However, there’s an exception as mentioned below.To write to the mapping files, the capability
CAP_SET{U, G}IDhas to be present in the context of the target process.If the data to be written to one of the files only contains a single line: The initial process in a user namespace is allowed to map its own effective UID/GID values from within the namespace.
Otherwise: Arbitrary mappings can be added by a process residing in the parent namespace.
Depending on the namespace a process resides in, there exist differences in how the ID-outside-ns values are being interpreted. Consider the figure below illustrating this scenario. A user with UID 1000 creates two namespaces with different ID mappings. After that, the initial processes of both namespaces read the applied mappings of each other:
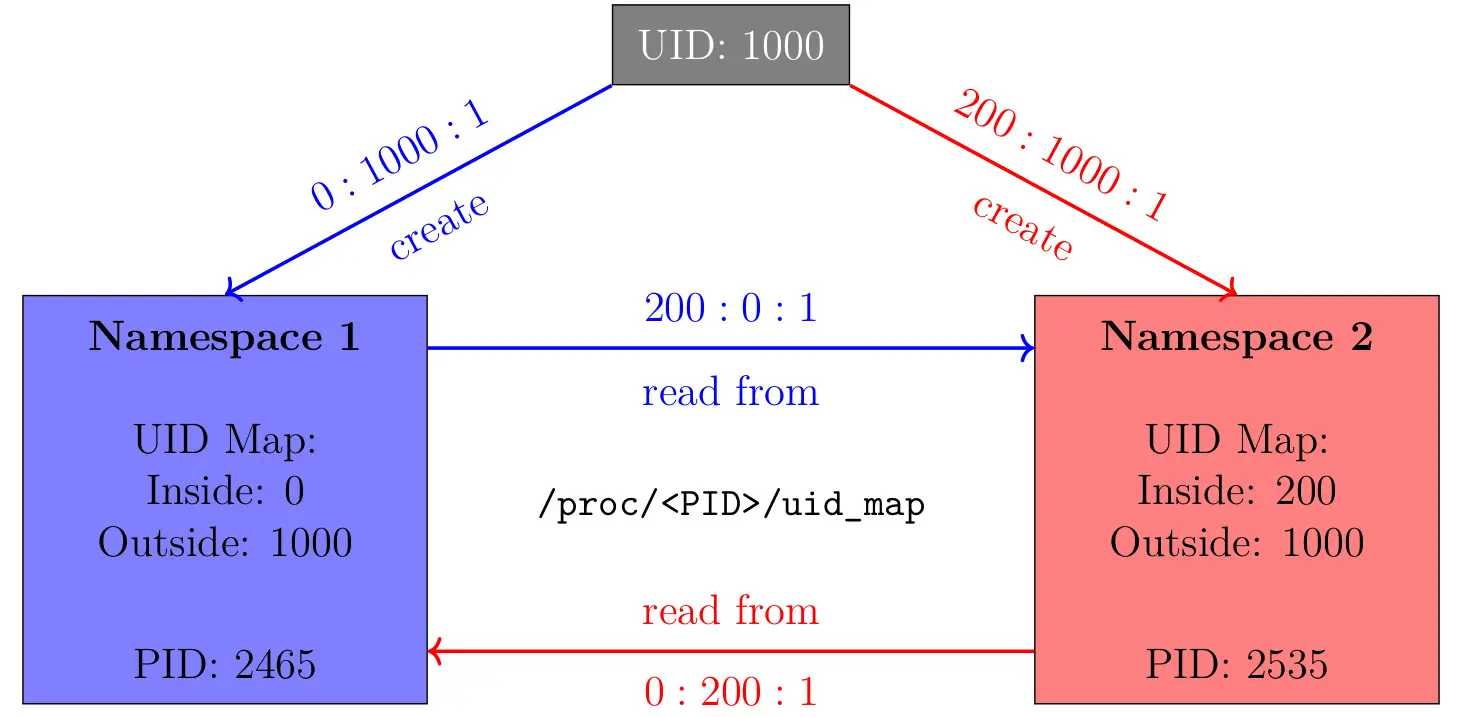
Consider the initial process writing to its own mapping file: To map the user identifier 1000 to its root user, a namespace has to use the same configuration as the one which namespace 1 receives above. This results in the ID-outside-ns value having to be interpreted as a UID of the parent namespace in case two processes reside in the same namespace.
However, if they are in different namespaces, as seen above, something else can be observed: ID-outside-ns is interpreted as being relative to the namespace the process that’s being read from is being placed in. Namespace 1 reads 200:0:1 from namespace 2 – this means that the UID 0 in namespace 1 corresponds to the ID 200 of namespace 2 and both originate from the user identifier 1000. The same applies to namespace 2 the other way around.
It’s possible to combine user namespaces with other namespace types. This enables users to create namespaces that would require CAP_SYS_ADMIN without being privileged. To accomplish this, one can use clone and a combination of CLONE_NEWUSER and other clone flags. The kernel processes the flag to create a new user namespace first and processes the remaining CLONE_NEW* flags inside the new user namespace.
Being privileged in a user namespace does not imply superuser access on the whole system. Nevertheless, the ability to perform actions an unprivileged user would not be able to execute without user namespaces also broadens the attack surface. For example unprivileged users are able to execute certain mount operations that can be the target of kernel exploits [3]. There may remain more potential security issues regarding user namespaces to be uncovered in the future. For example, it was previously discovered that the combination of user namespaces and the CLONE_FS flag can lead to a privilege escalation issue [4]. More recently it was discovered that when the limit for the number UID/GID mappings a namespace can have was increased from 5 to 340, a security issue [5] was introduced: When switching to different data structures to store the mappings in the kernel once the number of mappings exceeds five, this data is being accessed in a wrong way. This results in processes of nested user namespace being able to access files being owned by other namespaces, e.g. /etc/shadow of the initial user namespace.
Next post in series
- Continue reading the next article in this series Namespaces
Kernel
View
and
Usage
in
Containerization
Follow us on Twitter , LinkedIn , Xing to stay up-to-date.
Credits
Credits: The elaboration and software project associated to this subject are results of a Master’s thesis created at SCHUTZWERK in collaboration with Aalen University by Philipp Schmied.