
Linux Container Primitives: Namespaces Kernel View and Usage in Containerization
Part six of the Linux Container series
October 15, 2020

After discussing the various types of namespaces in the previouspart of the Linux Container Primitive series, this post describes the internals of namespaces in the Linux kernel. Also, practical use-cases for namespaces in terms of containerization are considered. The following list shows the topics of all scheduled blog posts. It will be updated with the corresponding links once new posts are being released.
- AnIntroductiontoLinuxContainers
- LinuxCapabilities
- AnIntroductiontoNamespaces
- TheMountNamespaceandaDescriptionofaRelatedInformationLeakinDocker
- ThePIDandNetworkNamespaces
- TheUserNamespace
- NamespacesKernelViewandUsageinContainerization
- AnIntroductiontoControlGroups
- TheNetworkandBlockI/OControllers
- TheMemory,CPU,FreezerandDeviceControllers
- ControlGroupsKernelViewandUsageinContainerization
Namespaces Kernel View
This section covers aspects of the Linux kernel code regarding the implementation of namespaces. For this, various points, such as tasks, credentials and namespace proxies are being taken into account. In the kernel source code, these are all represented by C structures [1]:
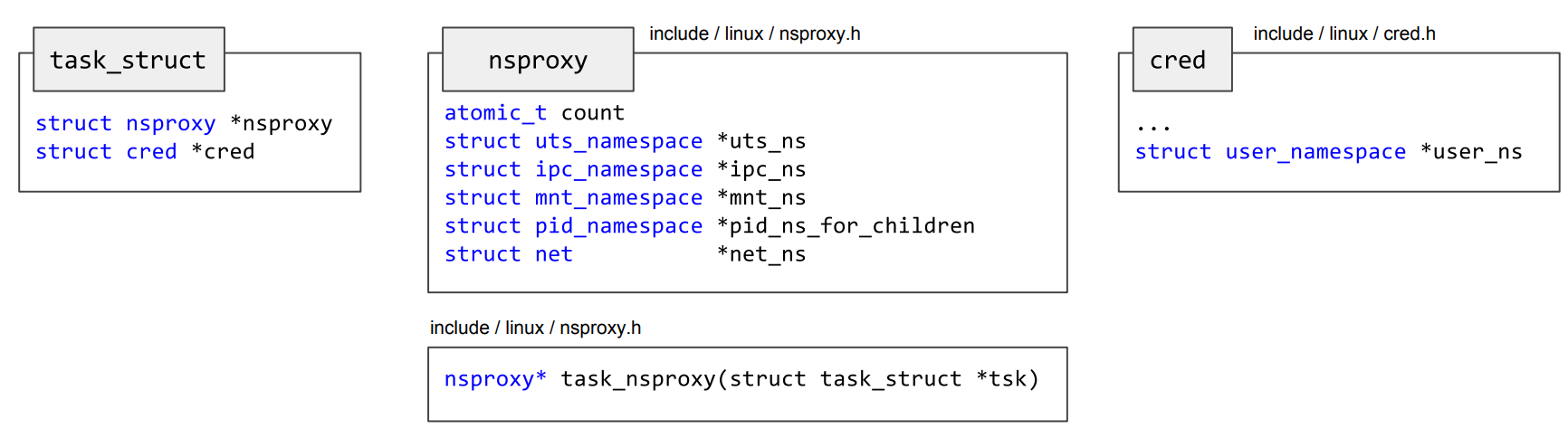
From a kernel point of view, processes are often called tasks. The kernel keeps track of them by storing task information in a doubly linked list. This list is called task list and contains elements of the task_struct type, as defined in linux/sched.h. These structures act as task descriptors and contain all relevant information on a task, for example:
- The process identifier (
pid_t pid) - Managed file descriptors (
files_struct *files) - Pointer to the parent task (
task_struct *parent) - Namespace proxy (
nsproxy *nsproxy) - Task credentials (
cred *cred)
Using the credential information listed above, the Linux kernel manages the associated ownership information of certain objects, such as files, sockets and tasks. Upon requesting an action to be performed on an object, for example writing to a file, the kernel executes a security check in order to determine whether a user is allowed to perform an action in regard to the task’s associated credentials. The cred structure is defined in linux/cred.h and contains a user_namespace pointer. This is required because credentials are relative to the specific user namespace that’s currently active.
To associate a task to the namespace it currently runs in, the nsproxy kernel structure contains a pointer to each per-process namespace. The PID and user namespace are an exception: The pid_ns_for_children pointer is the PID namespace the children of the process will use. The currently active PID namespace for a task can be found in the task_active_pid_ns pointer. Moreover, the user namespace is a part of the cred structure as seen above.
For an example of the linked kernel structures, consider the association of a task to a specific UTS namespace in the figure [1] below:
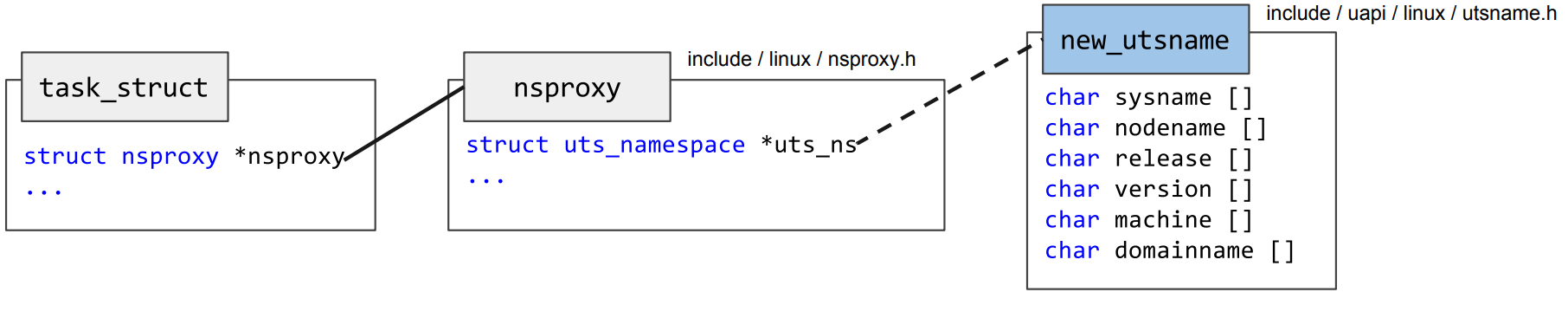
This implies that other parts of the kernel code also have to be aware of namespaces, e.g. when returning a hostname upon accessing this information from a task. This is implemented by modifying the original code of gethostname in order to read the hostname of the current namespace and not from the system’s hostname. The namespace unaware version of this function is listed below:
[...]
i = 1 + strlen(
system_utsname.nodename);
[...]
if (copy_to_user(
name,
system_utsname.nodename,
i))
[...]
The modified version for namespaces follows below:
[...]
u = utsname();
i = 1 + strlen(u->nodename);
[...]
memcpy(tmp, u->nodename, i);
[...]
if (copy_to_user(name, tmp,
i)
)
[...]
The call to utsname is being used in namespace aware versions of the gethostname call to determine the desired hostname value using the nsproxy kernel structure mentioned above:
static inline struct new_utsname *utsname(void)
{
return ¤t->nsproxy->uts_ns->name;
}
Upon creating a child process, the elements of the nsproxy structure will be copied as the child will reside in the exact same namespaces the parent lives in. This can be observed in the copy_process function called in do_fork. By using copy_namespaces, the members of the parent’s nsproxy structure are being duplicated:
static struct nsproxy *create_new_namespaces(unsigned long flags,
struct task_struct *tsk, struct user_namespace *user_ns,
struct fs_struct *new_fs) {
struct nsproxy *new_nsp;
int err;
// Create a new namespace proxy
new_nsp = create_nsproxy();
[...]
// Copy the existing UTS namespace (among others)
new_nsp->uts_ns = copy_utsname(flags, user_ns,
tsk->nsproxy->uts_ns);
[...]
}
Upon using unshare, the ksys_unshare function is being executed. This calls unshare_nsproxy_namespaces which effectively leads to the nsproxy structure being copied, modified according to the unshare call and replaced as soon as one element of the structure is being modified.
Every nsproxy structure contains a count element. This counter keeps track of how many tasks refer to the same nsproxy. After a task terminates, the count value of the associated nsproxy gets decremented and in case there’s no other task using a specific nsproxy, it gets freed along with all contained namespaces:
void free_nsproxy(struct nsproxy *ns) {
// Check if the namespace is still in use, free if unsued
if (ns->mnt_ns)
put_mnt_ns(ns->mnt_ns);
if (ns->uts_ns)
put_uts_ns(ns->uts_ns);
if (ns->ipc_ns)
put_ipc_ns(ns->ipc_ns);
if (ns->pid_ns_for_children)
put_pid_ns(ns->pid_ns_for_children);
put_cgroup_ns(ns->cgroup_ns);
put_net(ns->net_ns);
kmem_cache_free(nsproxy_cachep, ns);
}
The put_*_ns functions seen above are responsible for destroying unused namespaces of a specific type. Of course, this only happens in case no other task uses the particular namespace anymore.
When entering a namespace using setns, the function switch_task_namespaces is being used:
void switch_task_namespaces(struct task_struct *p,
struct nsproxy *new) {
struct nsproxy *ns;
[...]
// lock the task before switching namespace
task_lock(p);
// switch namespace
ns = p->nsproxy;
p->nsproxy = new;
task_unlock(p);
// delete the old namespace proxy if unused
if (ns && atomic_dec_and_test(&ns->count))
free_nsproxy(ns);
}
Moving a task to a specific namespace can be as simple as setting the respective pointers of the nsproxy structure.
Usage in Containerization
Both LXC and Docker apply a standard namespace configuration in case no further configuration is supplied. This involves setting up a new namespace for each type that has been discussed in this chapter and that’s also supported by the kernel. Specific namespace configuration can be applied using the Docker CLI and LXC configuration files.
Additional configuration may include supplying a specific namespace a container is joining. For example, the --net=host option disables creating a new network namespace for a Docker container, allowing it to join the initial network namespace. Therefore no network isolation is in place and for instance localhost in a container points to localhost of the host, creating a behavior as if a process is running without containerization in regard to its available network environment. This allows flexible setups by allowing the user to choose the isolated resources freely.
Docker configures user namespaces in a way that maps a non-existent UID as root in a container. Therefore, escalating to another user namespace by abusing a potential vulnerability does not add any privileges [2]. This is being performed by using the /etc/sub{u, g}id files. By creating a subordinate ID mapping in these files, a range of non-existing IDs is assigned to each real user of the host. This ensures that the ranges do not overlap and are in fact disjunct. Using this range non-existing users are being mapped into a container, starting from a zero value which corresponds to root.
Next post in series
- Continue reading the next article in this series AnIntroductiontoControlGroups
Follow us on Twitter , LinkedIn , Xing to stay up-to-date.
Credits
Credits: The elaboration and software project associated to this subject are results of a Master’s thesis created at SCHUTZWERK in collaboration with Aalen University by Philipp Schmied.