
Power analysis based software reverse engineering assisted by fuzzing II
Part two of the power analysis series
September 3, 2020

In the previouspost a setup and a technique to extract a representative section of a powertrace of a specific instruction of a STM32F3 processor were described. This section is called a “template”. These templates should later be used to identify instructions via a power sidechannel and reconstruct the flow of an unknown program on a controller that can not be dumped via JTAG. In this part of our poweranalysis series the extracted templates from the previous post will be analyzed to determine whether they are representative enough to reverse engineer entire programs from a powertrace. The following list shows the topics of all scheduled blog posts. It will be updated with the corresponding links once new posts are being released:
- Goalsandtemplateextractionprocess
- Templateanalysisandreverseengineering
- Fuzzing based on reconstructed flow
Is the powertrace unique to one specific chip?
To reverse engineer a program from a controller that can not be programmed, the templates from another chip of the same series have to be portable. In order to test that the templates are portable between multiple controllers of the same series, an instruction series has been recorded on two STM32F3s. The tested instructions used in this example contained a series of one thousand random mathematical instructions. The recorded traces of this series are shown in the following plot.
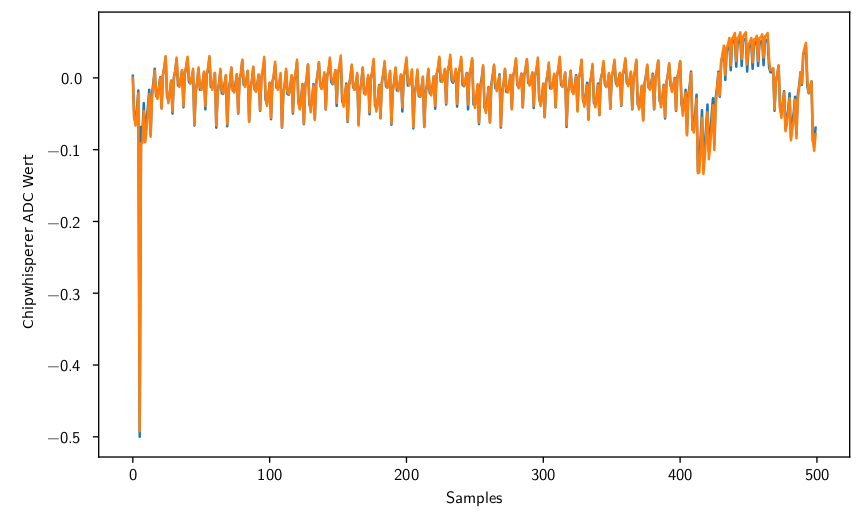
Both look very similar besides some minor variations. If both are subtracted from each other the following signal is obtained:
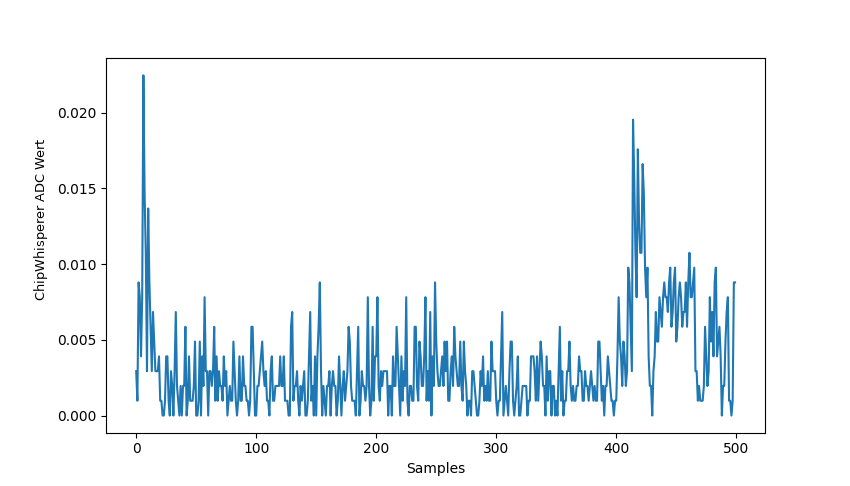
This difference is nearly as low as the difference between two recordings from the same chip. So a portability of the templates can be assumed.
Can arguments be detected?
Unfortunately not. The following plot shows for example an add instructions with different arguments. Although the traces have some minor variations, they could not be reliably correlated with a specific argument.
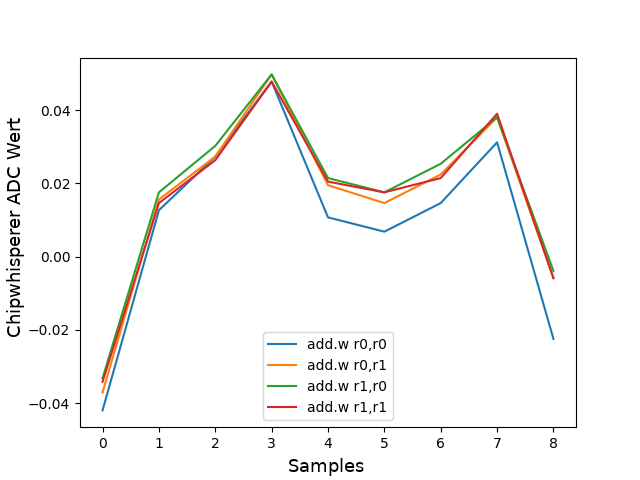
This problem might be solved with a higher resolution oscilloscope or machine learning to spot differences that a human could not.
How distinguishable are the Templates?
After some samples have been recorded, it has to be checked that they are distinguishable from each other. To accomplish this the same recorded instruction series can be correlated against all templates. In the following example a series of five ASR (arithmetical shift right) instructions, including some initialization and deinitialization code, is correlated with various templates.
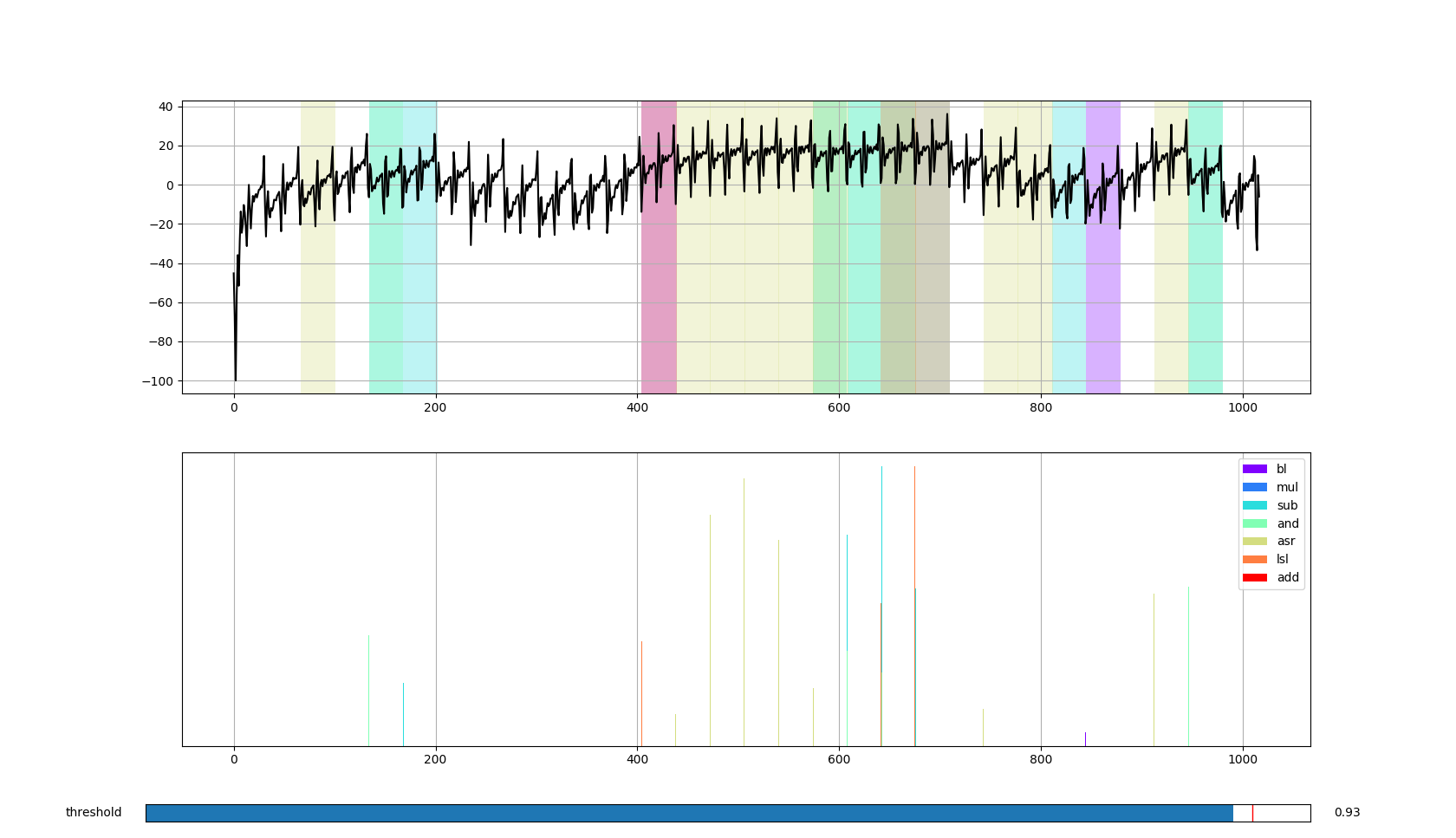
It can be assumed that at about sample number 400 a jump into the series occurs. The following five instructions match as expected to the ASR instruction. But if a series of five LSL (logical shift left) instructions is correlated with the templates some occurrences are mismatched with ASR instructions.
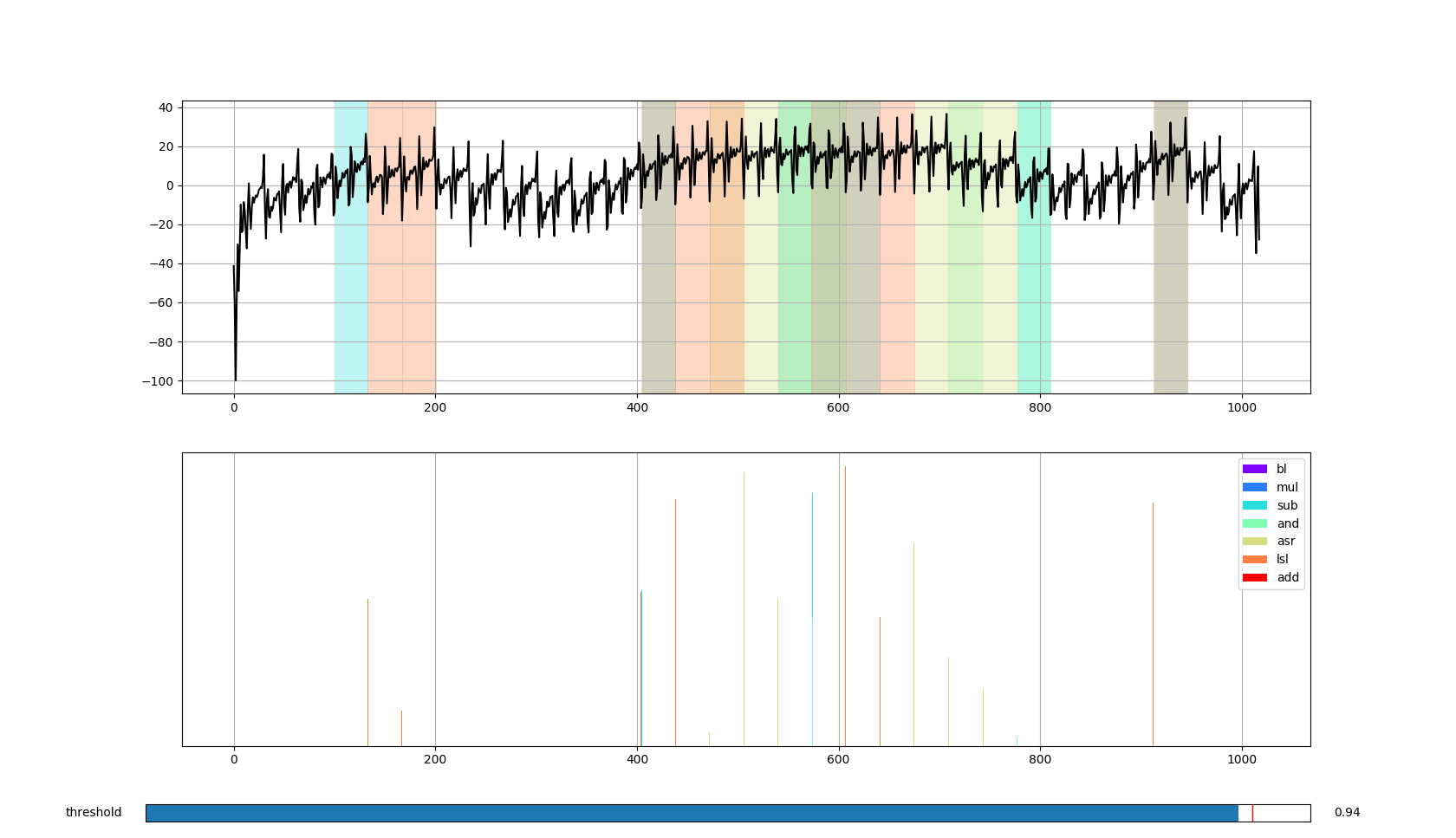
The same behavior can be seen with other ALU (arithmetic logic unit) instructions. The conclusion here is, that instructions that are processed by the same functional unit in the microcontroller can be mismatched. But instructions that are processed by different processing units can be distinguished easily. For example memory instructions:
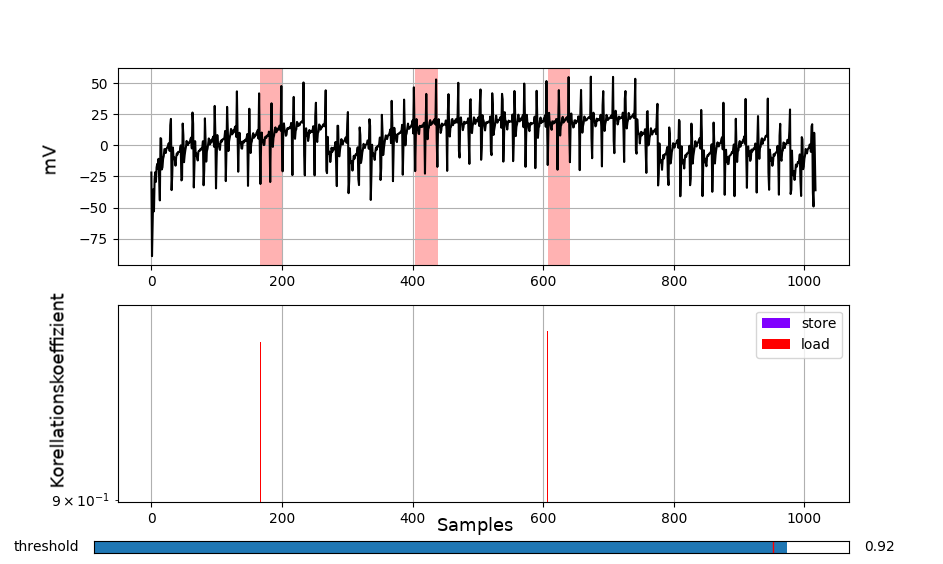
As it can be seen in the plot, no memory operation has been associated with the area of the add series.
Reconstructing a program
For program reconstruction, especially program flow reconstruction, there is no need to determine each instruction and each argument precisely. It is enough to detect jumps and then compare the traces of the executed codeblocks. If they correlate and have a similar length they could be assumed equal. This information could be used to reconstruct program loops. To validate this theory we use simple password checking function as an example.
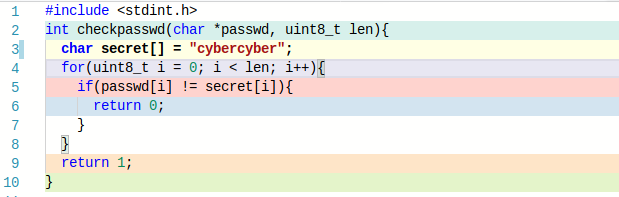
If the password “a” is entered the following graph can be reconstructed, when each edge is a detected jump and each node is a unique codeblock that does not correlate good with the others.
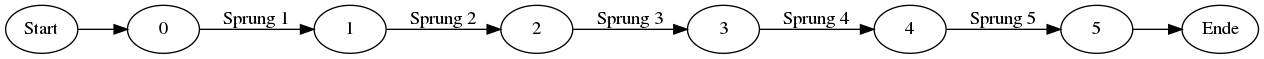
No loop is visible and a linear program flow is reconstructed, as expected from the source code. But if for example an input is given that is matching the first symbol of the password (like “ccc”) a pass of a loop becomes visible.
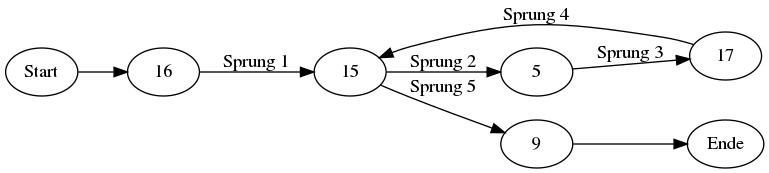
Such a clear representation of the programs flow can not always be expected. Sometimes jumps are not or falsely detected. Also the matching of codeblocks is not an easy task. If a codeblock contains a conditional jump it might be detected as a smaller block when the jump is executed and as a big block when the jump is not executed. And if blocks are always matched and aligned with the smallest block possible then all blocks fragment into tiny blocks of one to three instructions. The improvement of block matching algorithms is a current task of our research.
Next Post
- The next article in this series ‘‘Fuzzing based on reconstructed flow’’ will be published soon.
Follow us on Twitter , LinkedIn , Xing to stay up-to-date
References / Credits
The work was sponsored by the BMBF project SecForCARs and created at SCHUTZWERKGmbH (supervisor Dr. Bastian Könings & Msc. Heiko Ehret) in cooperation with the InstituteofDistributedSystems at Ulm University (referee: Prof. Dr. Frank Kargl, supervisor Dr. Rens van der Heijden).